Dialect Identification with Vaani and Respin Datasets

India, a land of immense linguistic diversity, presents a fascinating challenge: identifying a speaker’s dialect from their voice. As you travel across the country, you’ll notice subtle (and sometimes not-so-subtle) shifts in how a language is spoken. This project takes up this challenge, aiming to pinpoint a speaker’s dialect, using their district of origin as a proxy.
However, this isn’t a straightforward task. Two key things to keep in mind:
- People move! Inter-district migration is common, meaning a speaker’s current location might not reflect their native dialect.
- We’re venturing into new territory. Prior work on dialect identification in Indian languages is scarce, so we’re building our understanding from the ground up. This also means, a lack of baseline to compare our results against.
The Vaani Dataset: A Massive & Diverse Dataset of Indian Voices⌗
Our models are powered by the Vaani dataset, an extensive collection of speech samples gathered across India.
Here’s a quick look at what makes Vaani special:
- Massive Scale: Roughly
16,000hours of speech data. - Rich Diversity: Covers
54Indic languages from80districts across12states. - Valuable Metadata: Includes district of recording, speaker demographics (where available), and language labels.
- Transcriptions: A small portion (
~5%) comes with manual transcriptions. - The Team Behind It: Developed by ARTPARK, IISc Bangalore, and Prof. Prasanta Kumar Ghosh (EE Dept, IISc), with funding from Google.
For our experiments, we carve out specific subsets from Vaani, focusing on particular states or languages, and use the district-level labels to train our models. We typically split the data into 80% for training, 10% for validation, and 10% for testing, making sure speakers don’t overlap between these sets to avoid skewed results. We also balance these subsets to have an equal number of samples for each dialect (district).
Our Approach: Testing Different Speech Models⌗
We finetuned several different pretrained models on this task and compared their performance on various subsets.
Wav2Vec2 and its Variants by Meta AI⌗
Wav2Vec2 is a popular framework that learns speech representations from raw audio in a self-supervised way. We experimented with:
- Wav2Vec2-Base / Large: Pre-trained mainly on English speech.
- Wav2Vec2-XLS-R (300M, 1B, 2B): Pre-trained on diverse multilingual speech data. This is a key difference!
- MMS (300M, 1B): Meta AI’s Massively Multilingual Speech models, trained on thousands of languages.
- Wav2Vec2-Conformer: Incorporates Conformer blocks for potentially better architectural performance.
These models are typically fine-tuned by adding a simple classification layer on top of their learned speech representations.
WavLM by Microsoft⌗
WavLM aims to create universal speech representations by learning from vast and varied datasets. It’s designed to excel at both understanding content (like in Automatic Speech Recognition - ASR) and paralinguistic tasks (like speaker or emotion recognition). This makes it a strong candidate for dialect identification, which relies on subtle acoustic and phonetic cues. We primarily used the WavLM-Base model. (Experiments with WavLM were conducted by Bingimalla Yasaswini.)
Vakyansh by EkStep Foundation⌗
Vakyansh offers Wav2Vec2 models pre-trained on English and then fine-tuned for specific Indian languages. We used a model fine-tuned on 96 hours of Telugu data, which itself was derived from their Hindi fine-tuned model. The base architecture is Wav2Vec2-Base. (Experiments with Vakyansh models were conducted by Bingimalla Yasaswini from Vision and AI Lab at IISc as part of this project.)
Experiments and What We Found⌗
We ran several experiments, focusing on different slices of the Vaani dataset.
Zooming in on Andhra Pradesh / Telugu Districts with Wav2Vec2⌗
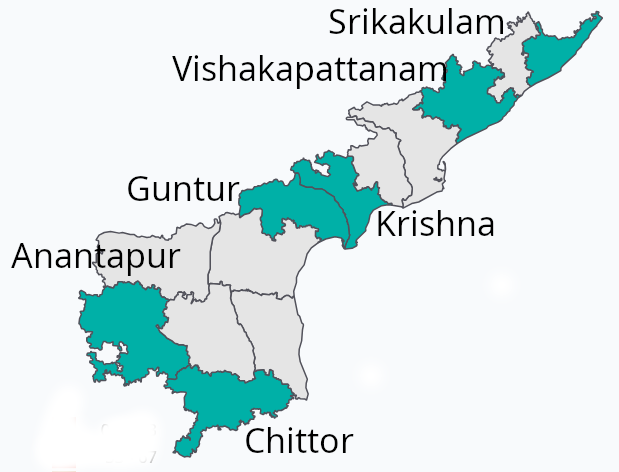
Our first deep dive was into distinguishing between 6 Telugu-speaking districts in Andhra Pradesh: Anantpur, Chittoor, Guntur, Krishna, Srikakulam, and Vishakapattanam.
- Initial Disappointment: Wav2Vec2-Base and Large (pre-trained on English) performed no better than guessing randomly (around 17% accuracy). This highlighted that English pre-training wasn’t cutting it for the nuances of Telugu dialects.
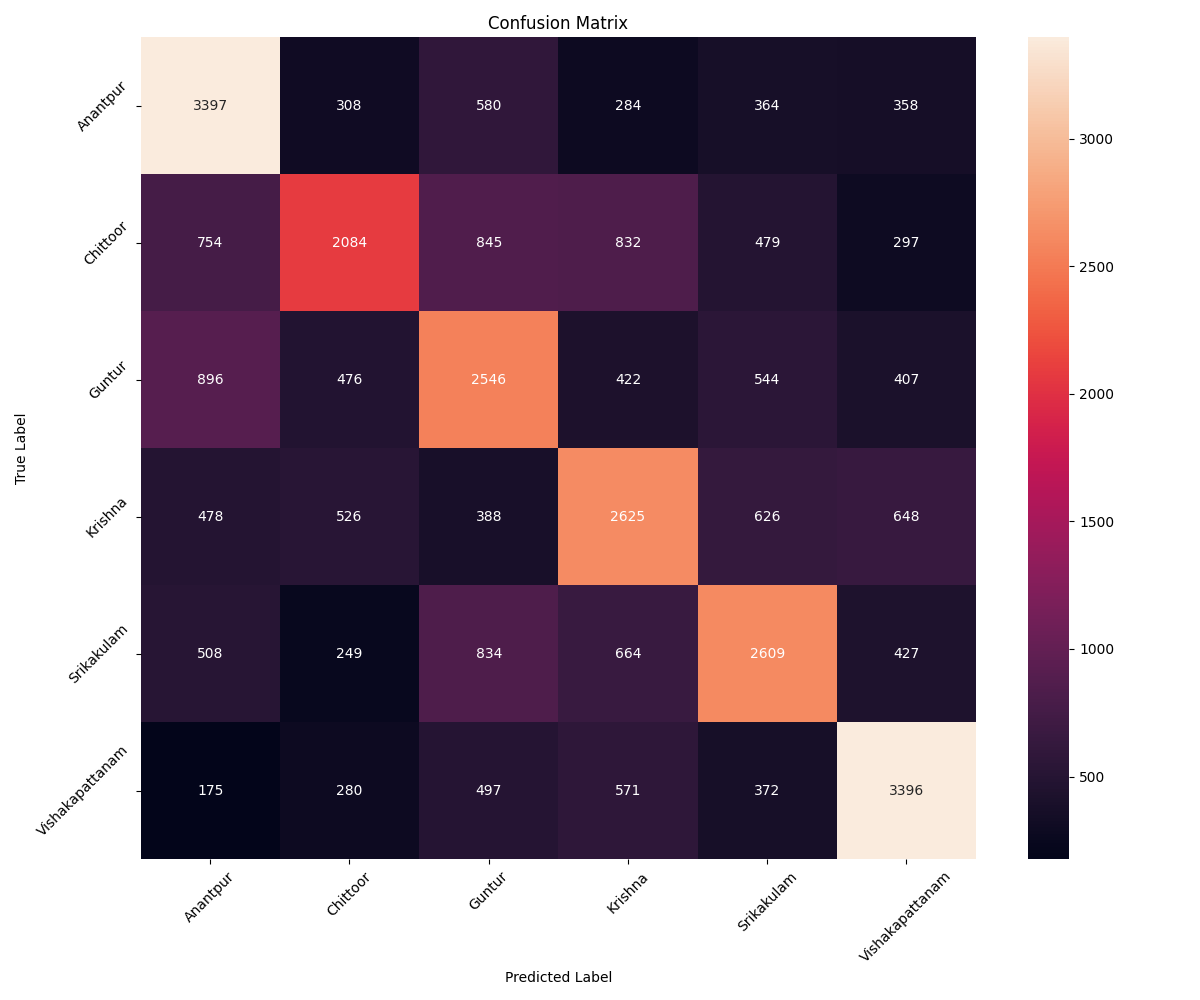
- The Multilingual Advantage: Wav2Vec2-XLS-R-300m, pre-trained on diverse languages, achieved a much better validation accuracy of 53% after just 5 epochs of fine-tuning! This strongly suggested that multilingual pre-training is crucial.
- MMS Shines Too: MMS-300m performed similarly to XLS-R, also hitting 53% validation accuracy.
- Conformer Falters (for now): Wav2Vec2-Conformer didn’t show significant improvement here, reaching only 35% accuracy. This might be due to its English pre-training and the need for more extensive multilingual fine-tuning. It was also slower to train due to its large size.
Here’s a look at the confusion matrix for the XLS-R model on the 6 Andhra Pradesh districts, alongside a map showing their locations. Interestingly, we didn’t find a clear link between how geographically close the districts are and how often the model confused them.
Tackling Hindi Language Districts⌗
We broadened our scope to 46 districts across various North Indian states where Hindi is prevalent. Using Wav2Vec2-XLS-R, we achieved an accuracy of about 35% on the validation set. This task was tougher, likely due to the larger number of classes and the linguistic diversity even within Hindi-speaking regions.
The districts included were: Araria, Begusarai, Bhagalpur, Darbhanga, East Champaran, Gaya, Gopalganj, Jahanabad, Jamui, Kishanganj, Lakhisarai, Madhepura, Muzaffarpur, Purnia, Saharsa, Samastipur, Saran, Sitamarhi, Supaul, Vaishali, Budaun, Deoria, Etah, Ghazipur, Gorakhpur, Hamirpur, Jalaun, Jyotiba Phule Nagar, Muzaffarnagar, Varanasi, Churu, Nagaur, Tehri Garhwal, Uttarkashi, Balrampur, Bastar, Bilaspur, Jashpur, Kabirdham, Korba, Raigarh, Rajnandgaon, Sarguja, Sukma, Jamtara, and Sahebganj.
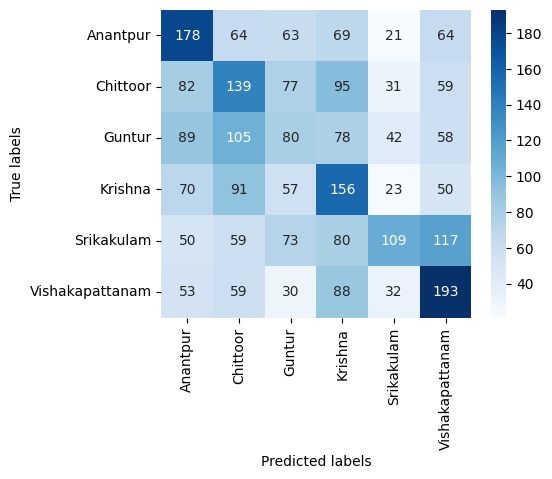
Andhra Pradesh / Telugu Districts with WavLM⌗
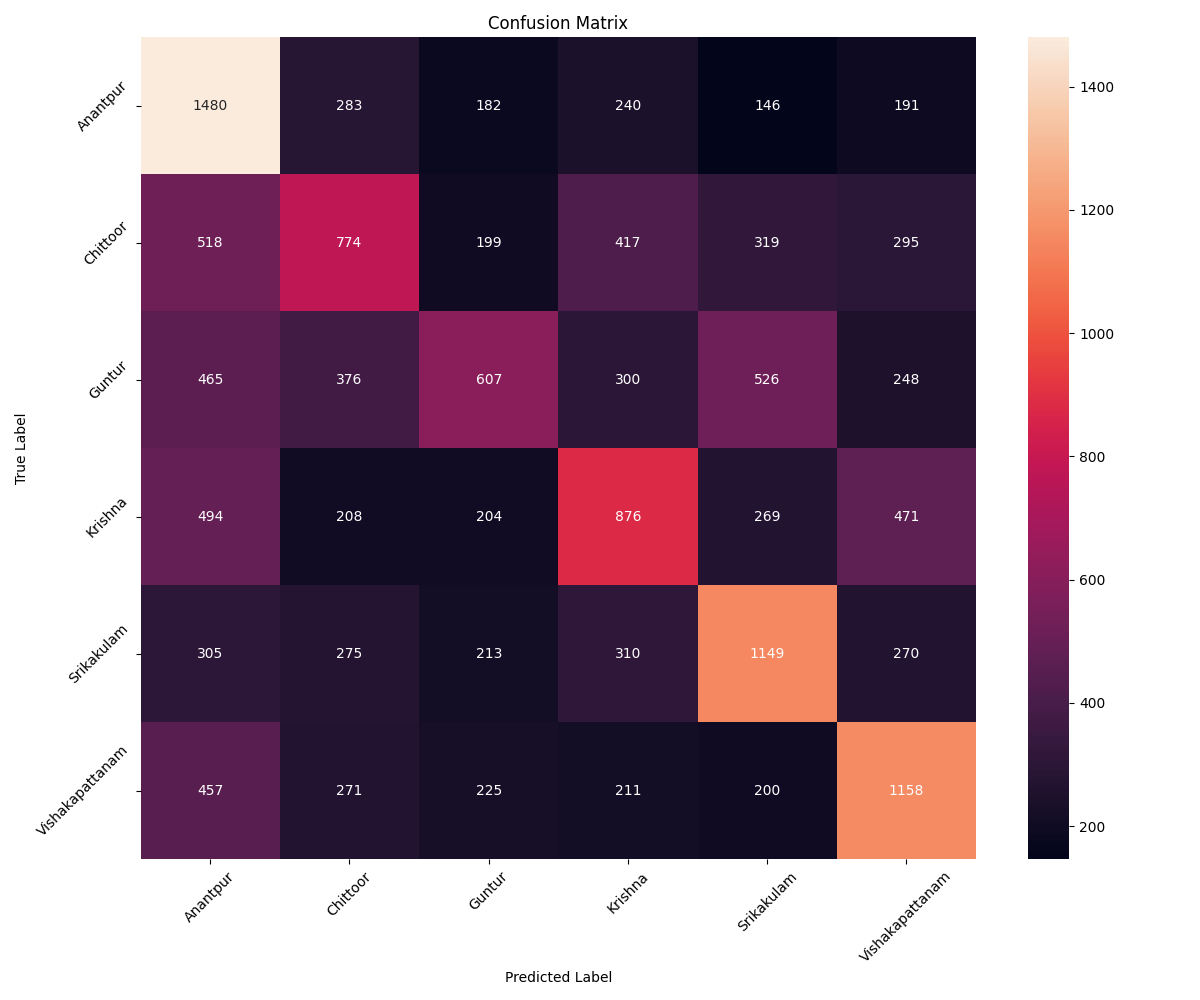
Fine-tuning the WavLM-Base model for 20 epochs yielded a validation accuracy of 39% for the 6 Andhra Pradesh Telugu districts.
The confusion matrix (below) shows that while the model often gets it right (diagonal elements), there’s still noticeable confusion between districts. Again, no obvious correlation with geographic proximity was observed.
A Diverse Multi-Language Challenge with WavLM⌗
To test how well WavLM generalizes across more distinct linguistic and geographic lines, we picked 12 districts, each from a different state (and likely a different language). The labels were: Anantpur, Araria, Balrampur, NorthSouthGoa, Jamtara, Belgaum, Karimnagar, Aurangabad, Churu, Budaun, TehriGarhwal, and DakshinDinajpur.
Performance varied quite a bit, with some districts like Belgaum being identified more accurately.
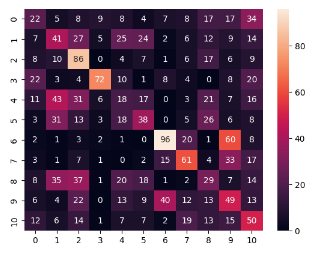
Vakyansh Telugu Model Results⌗
Using the Vakyansh Wav2Vec2 model (fine-tuned for Telugu), we again targeted the 6 Andhra Pradesh districts, achieving a validation accuracy of 29%.
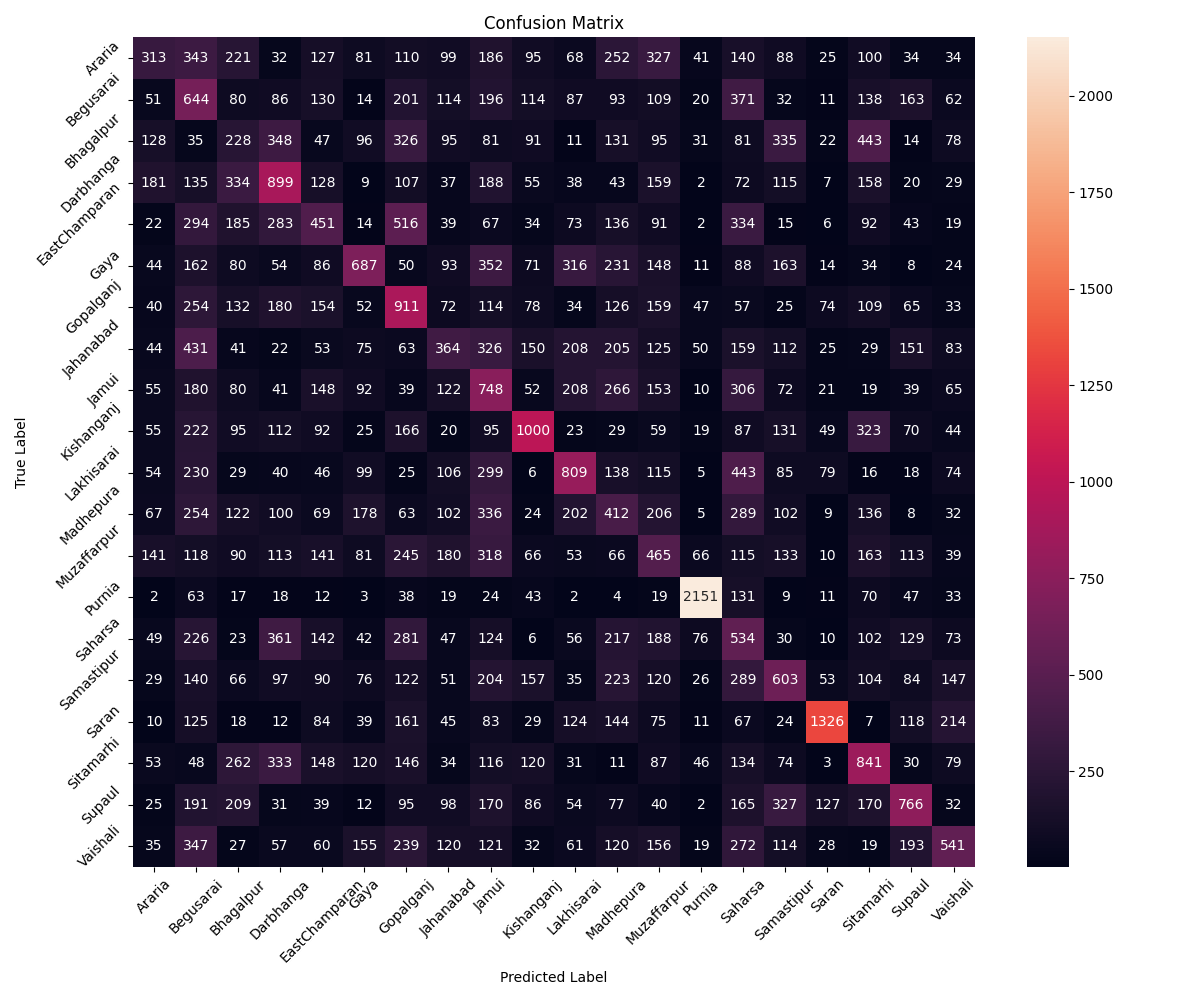
WavLM on Bihar Districts⌗
We also tested WavLM on 20 districts from Bihar (primarily Hindi-speaking). After filtering the dataset to include female speakers with over 20 years of residency in their respective districts, the model achieved an accuracy of 26%.
What Didn’t Work So Well (Negative Results)⌗
Our early experiments quickly showed that models pre-trained mostly on English (Wav2Vec2-Base, Wav2Vec2-Large, and even Wav2Vec2-Conformer in our setup) struggled significantly with the Telugu dialect task compared to multilingual models like XLS-R, MMS, and WavLM. This strongly suggests that pre-training on diverse, multilingual data, ideally including Indic languages, is crucial for this kind of task. The gap between English pre-training and Indic language fine-tuning seems too wide to bridge effectively for such subtle dialect distinctions.
Key Takeaways and Discussion⌗
These experiments underscore the difficulty of fine-grained, district-level dialect identification, even with a large dataset like Vaani.
- Multilingual Pre-training is Key: Models pre-trained on diverse languages (XLS-R, MMS, WavLM) consistently outperformed those trained primarily on English.
- Moderate Success: We achieved accuracies in the 30-50% range for 6-class problems, which is promising but shows there’s room for improvement.
- Data Filtering Helps: Filtering audio samples to be at least 5 seconds long boosted performance by about 10% for Wav2Vec2-XLS-R.
- No Simple Geographic Link: For the Andhra Pradesh case, we didn’t see a strong connection between districts being confused by the model and how close they are geographically. This could mean dialect boundaries are more complex than just adjacency, or that models might be picking up on other speaker or recording-specific details rather than pure dialectal features.
What’s Next? Future Directions⌗
We’re excited about several avenues to improve district-level dialect identification:
- State-of-the-Art Models: We plan to evaluate newer, powerful models like Whisper (known for strong multilingual abilities) and other recent ASR models.
- Indic Language Specialists: Using models specifically pre-trained on large Indic language corpora, like IndicWav2Vec, is high on our list.
- Advanced Architectures: We might revisit Wav2Vec2-Conformer with appropriate multilingual pre-training or explore architectures like w2v-bert-2.0 (used in SeamlessM4T) that integrate text and speech.
- ASR as an Auxiliary Task: We’re working on training dialect ID as a secondary goal to ASR. This involves modifying transcripts (e.g., adding a dialect token like
<telugu_chittoor> transcript...) and training an end-to-end ASR model. The idea is that forcing the model to understand the content might help it learn dialectal features more effectively. - Two-Stage Approach: Building on the auxiliary task idea, we could use the output of the ASR/dialect model (predicted dialect and transcript) along with the original audio as input to a second, more specialized classifier.
- Multi-Task and Transfer Learning: We’re considering “double fine-tuning” – perhaps using cleaner dialect-labeled datasets (like Respin, if applicable) either before or after fine-tuning on Vaani’s district labels.
Conclusion⌗
Our journey into district-level dialect identification in India using the Vaani dataset has been revealing. Multilingual pre-trained models like Wav2Vec2-XLS-R and MMS show the most promise so far, achieving respectable accuracies (around 50-53%) for a 6-district Telugu classification task. However, the challenge is significant, with considerable confusion between dialects. Future efforts will focus on leveraging cutting-edge multilingual models, exploring joint ASR and dialect ID training, and potentially using multi-stage approaches to better isolate those subtle dialectal cues in speech.
Acknowledgements: We thank Prof. Venkatesh Babu for his guidance and support, and VAI Lab for providing the compute resources. Karthik Dulam thanks Bingimalla Yasaswini for her work on the WaveLM and Vakyansh model experiments and her valuable feedback. We also thank the creators of the Vaani dataset (ARTPARK, IISc, Google) and the developers of the open-source models and libraries used. Special thanks to Saurabh Kumar from SPIRE lab for his insightful inputs.